This tutorial will expand this PxL script to produce a table that summarizes the total amount of traffic coming in and out of each of the pods in your cluster.
Adding Context
The ctx function provides extra Kubernetes metadata context based on the existing information in your DataFrame.
Because the conn_stats table contains the upid (an opaque numeric ID that globally identifies a process running inside the cluster), PxL can infer the namespace, service, pod, container and command that initiated the connection.
Let's add columns for pod and service to our script.
1# Import Pixie's module for querying data
2import px
3
4# Load the last 30 seconds of Pixie's `conn_stats` table into a Dataframe.
7# Each record contains contextual information that can be accessed by the reading ctx.
8df.pod = df.ctx['pod']
9df.service = df.ctx['service']
10
11# Display the DataFrame with table formatting
12px.display(df)
Save and run your script using Pixie's Live CLI:
px live -f my_first_script.pxl
Your CLI output should look similar to the following:
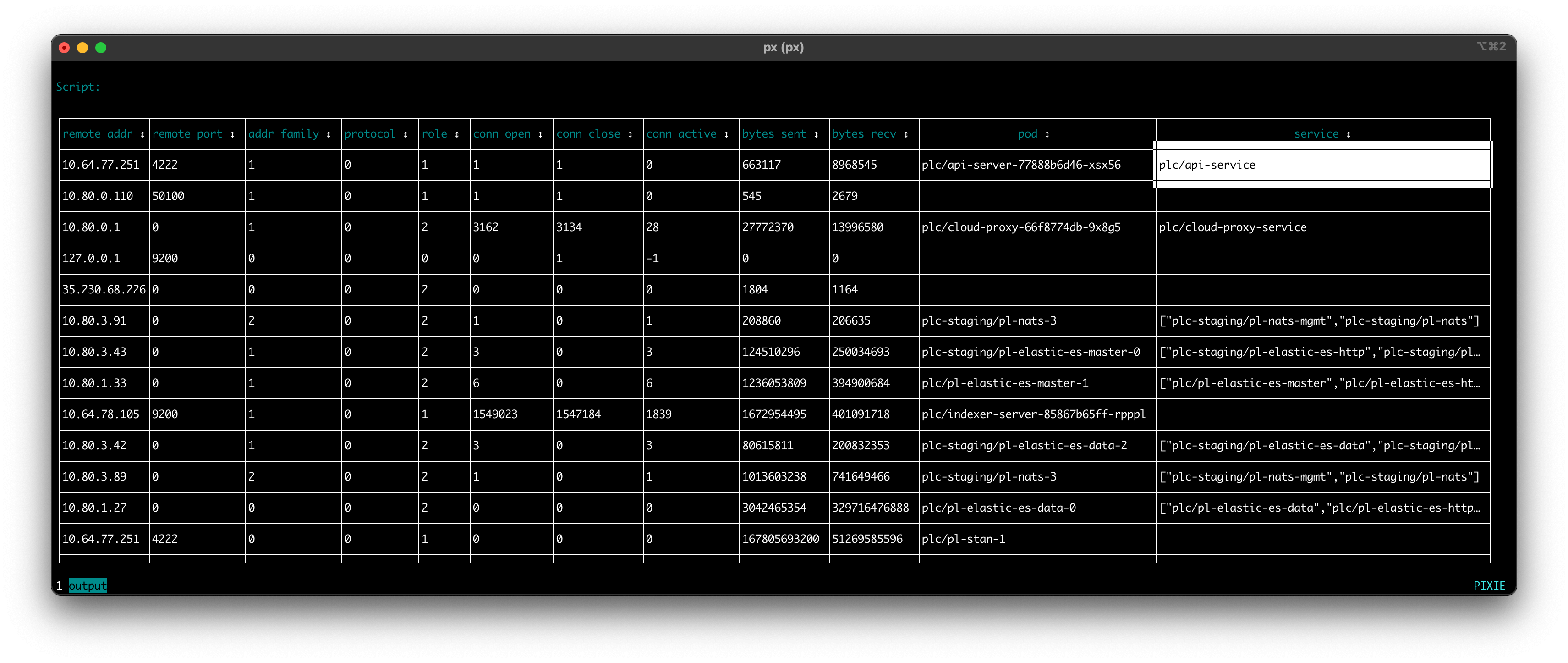
Script output in the Live CLI after adding pod and service metadata columns.
Use your arrow keys to scroll to the far right of the table and you should see a new columns labeled pod and service, representing the kubernetes entity that initiated the traced connection. Note that some of the connections in the table are missing context (a pod or service). This occasionally occurs due to a gap in metadata or a short-lived upid.
Grouping and Aggregating Data
Let's group the connection data by unique pairs of values in the pod and service columns, computing the aggregating expressions on each group of data.
PxL does not currently support standalone groupings, you must always follow the `groupby()` call with a call to `agg()`. However, the agg() call can take zero arguments. A full list of the aggregating functions is available here.
1# Import Pixie's module for querying data
2import px
3
4# Load the last 30 seconds of Pixie's `conn_stats` table into a Dataframe.
25# Calculate connection stats for each unique pod. Since there
26# may be multiple processes per pod we perform an additional aggregation to
27# consolidate those into one entry.
28df = df.groupby(['service','pod']).agg(
29 bytes_sent=('bytes_sent', px.sum),
30 bytes_recv=('bytes_recv', px.sum),
31)
32
33# Display the DataFrame with table formatting
34px.display(df)
Pods can have multiple processes, so on line 12 we group our connection stats by unique service, pod and upid pair. Later in the script, we will aggregate the connection stats into a single value per pod.
The conn_stats table reference docs show that the bytes_sent and bytes_recv columns are of type METRIC_COUNTER.
A counter is a cumulative metric that represents a single monotonically increasing counter whose value can only increase or be set to zero on restart. For example, Pixie uses a counter to represent the number of bytes sent to a remote endpoint since the beginning of tracing.
A guage is a metric that represents a single value that can arbitrarily increase or decrease. For example, Pixie uses a guage to represent the number of active connections with a remote endpoint.
Since we're interested in knowing the number of bytes sent and received over the last 30 seconds, we calculate the min (starting value) and the max (ending value) for each unique pod process. On line 22 we subtract these two values to find the total bytes sent and received over the time window.
On line 28, we group the connection stats for each unique pod, aggregating the values for each pod process.
Save your script, exit the Live CLI using ctrl+c and re-run the script.
Your CLI output should look similar to the following:
Script output in the Live CLI after grouping and aggregating the data.
Each row in the output represents a unique pod and service pair that had one or more connections traced in the last 30 seconds. All of the connections between these pod / service pairs have had their sent- and received- bytes summed for the 30 second time period.
Filtering
Let's filter out the rows in the DataFrame that do not have a service identified (an empty value for the service column).
1# Import Pixie's module for querying data
2import px
3
4# Load the last 30 seconds of Pixie's `conn_stats` table into a Dataframe.
25# Calculate connection stats for each unique pod. Since there
26# may be multiple processes per pod we perform an additional aggregation to
27# consolidate those into one entry.
28df = df.groupby(['service','pod']).agg(
29 bytes_sent=('bytes_sent', px.sum),
30 bytes_recv=('bytes_recv', px.sum),
31)
32
33# Filter out connections that don't have their service identified.
34df = df[df.service !='']
35
36# Display the DataFrame with table formatting
37px.display(df)
Save your script, exit the Live CLI using ctrl+c and re-run the script.
Your CLI output should look similar to the following. Note that the script output no longer shows rows that are missing a service value.
Script output in the Live CLI after filtering out rows without a service identified.
Conclusion
Congrats! You have written a script that produces a table summarizing the total amount of traffic coming in and out of each of the pods in your cluster for the last 30 seconds.
This script could be used to:
Examine the balance of a pod's incoming vs outgoing traffic.
Investigate if pods under the same service receive a similar amount of traffic or if there is an imbalance in traffic received.
In Tutorial #3 we will learn how to add more visualizations for this script.